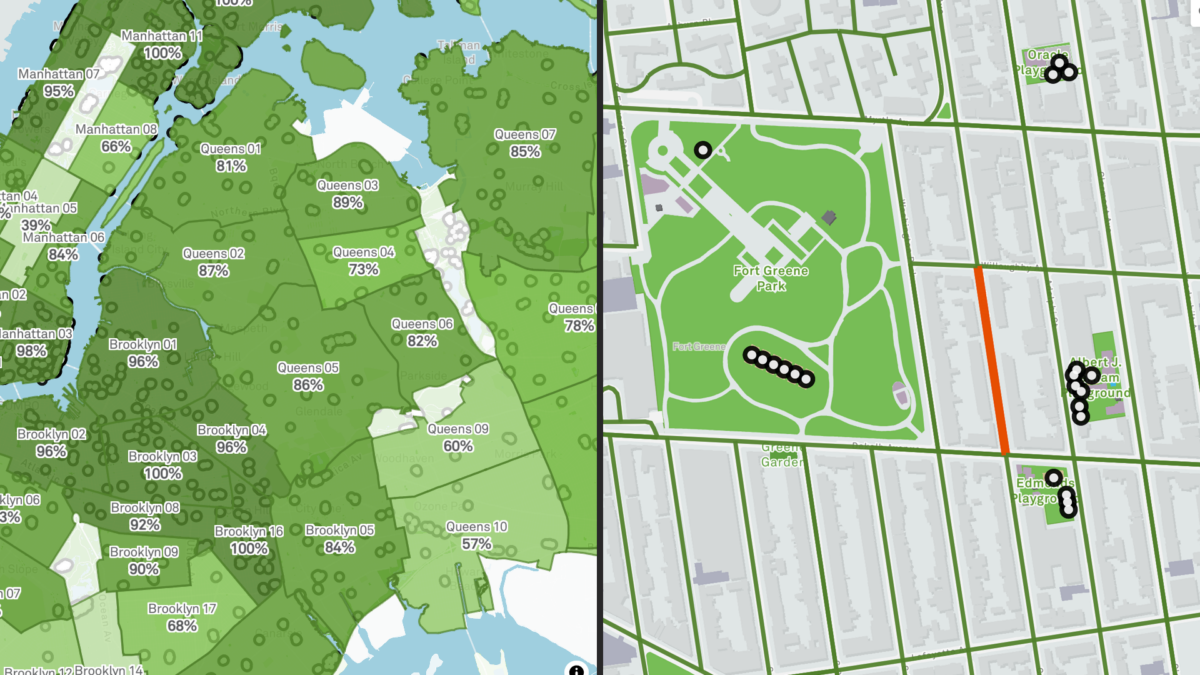
Annually, NYC community-based organizations and the City government work to supply millions of pounds of food directed toward people in need through the Community Food Connection Program. Determining how to distribute limited resources to where they are needed the most, the City leverages data-driven approaches to bring food to those in need using the Supply Gap Analysis. In this workshop, you’ll learn how data insights can shape decision-making, collaboration and support organizers like you to make more informed decisions that facilitate food security for our communities.
Led by the NYC Mayor’s Office of Food Policy, this session will include guests from the Mayor’s Office for Economic Opportunity & Community Food Connection Administrators, whose work supports over 700 food pantries and soup kitchens across the city, leveraging insights from the supply gap analysis in areas of unmet need.
Ideal for food security advocates, academics, students, data analysts and others interested in food-related issues and data, the workshop will provide answers to questions about neighborhood food security metrics, how need for emergency food is defined and measured, and how to leverage the dataset to support neighborhood and/or organizational strategies to close the gap. You will have a chance to interact with the Emergency Food Supply Gap dataset using NYC Open Data tools to pose your own strategic insights to support food security.