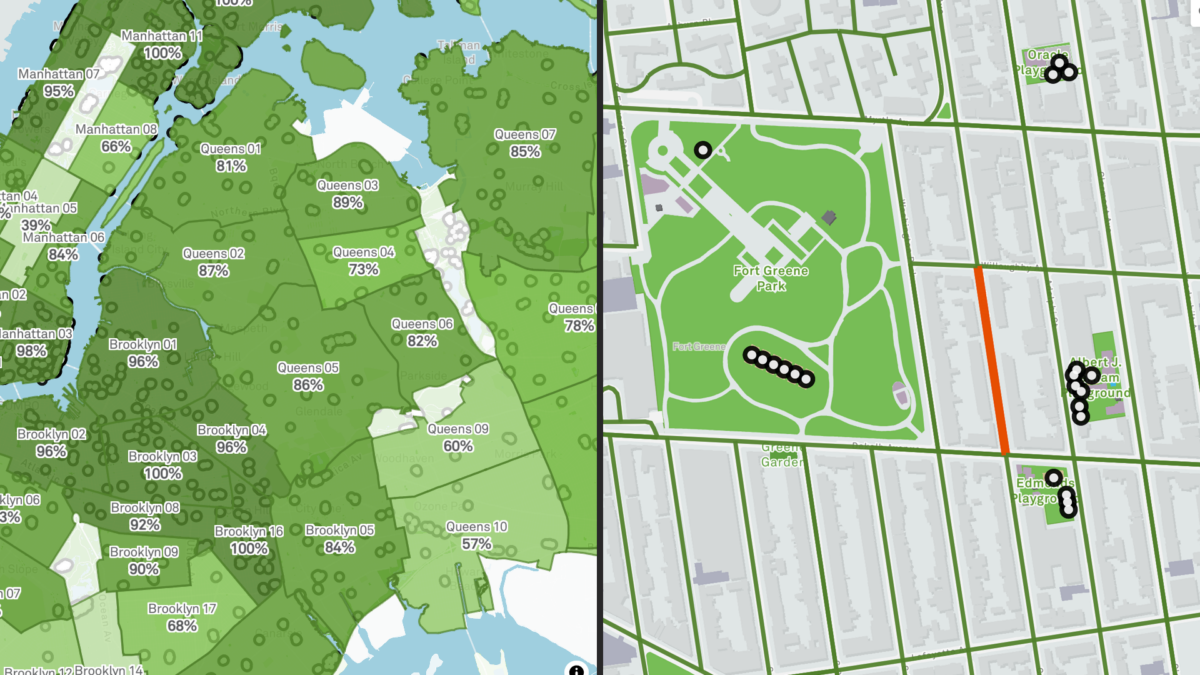
Have you ever wondered how parks in your neighborhood compare with others? Meet the Vital Parks Explorer! In this session, the Innovation & Performance Management (IPM) team from NYC Parks will share some highlights of how this public-facing tool was built. The Explorer visualizes access to parks amenities and services across the city. From inception and prototype, to public release, three data professionals working in local government will give you a behind-the-scenes look at how data, analysis, visualization, and user experience considerations shaped the final product. This event is for all New Yorkers who care about parks and might be of particular interest to advocates of public spaces, civic data enthusiasts, web app developers, designers, geospatial data scientists and engineers. We look forward to your participation and feedback!
Speaker bios:
Lilian Chin is a Data Analytics Specialist on Parks’ IPM team, where she has worked since September 2023. As part of IPM, she supports a wide-range of data-driven initiatives for Parks’ Maintenance and Operations. This includes visualizing the Work Order backlog, streamlining data pipelines for park assets, developing methodologies for the Park Condition Score, building in-house dashboards, and improving data quality and documentation.
Kate Sales is a Data Analytics Specialist on Parks’ IPM team. In the last year, she has worked on projects that touch many aspects of Parks including collecting and combining volunteer data for the Let’s Green NYC initiative, creating dashboards for Vital Parks for All, and helping others learn how to visualize data. Before Parks, Kate was a GIS analyst at the urban planning consulting firm Urban3 in Asheville, NC, her hometown. She recently completed her Master of Urban Planning at CUNY Hunter College and earned her BA in geography at Macalester College.
Benno Mirabelli is a Data Scientist on Parks’ IPM team. He works on various data analysis, reporting, research, and optimization projects. Some examples of his ongoing work include the routing analysis based on LION data for the recently released Vital Parks Explorer, research on understanding usership patterns and visitor volume at parks, and new management tools that assist with grass maintenance, planning, seasonal worker assignments and more. He holds a PhD in Applied and Computational Mathematics.